背景:
百度就是做搜索引擎的,那么显然而然公司对抓取这一块肯定是最深的,那么为什么还要来做这么一个小型的抓取框架了?主要原因是百度解决的是宽度和广度的问题,(就是尽可能覆盖全网所有的网页),所以会导致以下问题:
- 1. 时效性不够;(没办法保证所有网页都能得到及时的更新,因为数量大导致对网页的更新也是有优先级的)
- 2. 会形成孤点,公司的抓取都是扩链来进行抓取的,如果是孤点,不能进行抓取;
- 3.框架太大,接入太麻烦,还要审批;
而一般普通的抓取,主要需要解决以下需求:
- 1. 满足一般抓取的需求:(压力控制等)
- 2.需要渲染网页(js,css)
- 3.接入和实现简单;
- 4.由于一般的抓取多为结构化需求,还需要自动的解析功能;
难点主要存在在以下几点:
- 1. 扩展性好,需要支持多种浏览器内核进行抓取;
- 2.交互性好,主要是让用户可以快速的抓取想要的数据,所以在实现的过程中,交互和数据要尽可能分离,降低用户进入门槛;
解决方案:
主要做了两套系统,一套是前端的业务系统,另外一套是后端的实现系统:
业务系统帮助小白能够快速接入,基本零学习就能进行网页抓取,具体可以看以下两张图片:


业务系统主要是帮助客户能够简单的一键就进行抓取,这是一个纯交互的事情,基本上就是告诉pm或者其他的同学,这个事情很简单,后端的支持是抓取框架,但是实际上对大部分的系统来说,后端系统做起来很简单,难的是前端的交互,百度这么多的产品,内部系统、商业产品就不说了,基本上没有几个交互好的,用户产品基本也就是做的好的,继续还不错,做的差的,还有几十几百个。。这些离题远了:
抓取系统主要分为4块,scheduler,downloader,parser,extractor:
- scheduler,主要处理任务调度,保证单一网站不能因为一次抓取太多直接导致网站挂掉;
- downloader,主要是抓取网页,这一块要保证可扩展性,可以通过各种浏览器内核(firefox,webkit)或者直接curl这些直接抓取
- parser,主要是做结构化解析,这一块要保证两点1.解析模板的配置简单,上手容易,2.可以支持复杂的解析策略
- extractor,主要是各个自应用自己的处理逻辑,主要是做一些数据清洗;
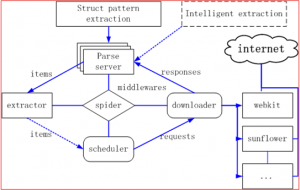
整体保证是一个环,然后每一个部分都是可以扩展的,这是最简单的一个抓取系统,每个模块都能够独立的拆分,也能满足简单可依赖的原则
效果:
这个系统最开始是1个人设计,然后变成3个人开发,最后变成1个人维护,一共做了1个多月,能够满足每天上百万的简单抓取,大部分反馈是正向的,看到公司另外一个团队,先做不知道多久,做了1、2年还是个烂样子不好用,等我述职的时候还问我,为啥你不用xx系统呀,我想说的是,你做了1,2年的系统还没有我们做的一个月的系统好用,接入还要这个领导那个领导批,我能用你的么?