最近在学习的时候,用到bagging和boosting的方法,所以在这里做一个简单介绍;
我们在做机器学习的时候,经常会很头疼,很多时候,我们选了不少的特征,做了很多的优化,但是准确率和召回率,到了一定的程度,他就不上去了,这种时候就会很头疼,当然这种时候也有很多的解决方法,增加数据集、换模型、优化特征清洗都是不错的方法等等,这里介绍另外一种思路,去解决这些问题;
提出bagging算法的人,其实我想就是受了日常一个非常简单的原理启发:当我们遇到一个问题不是很清楚,或者大家有分歧的时候,大家用的最简单的方法,就是投票吧,把这个理论应用到机器学习,bagging就是最简单的resample方法,通过从一个训练集随机选出N个子训练集,然后用来训练模型,训练出来的模型准确率只要大于0.5就可以留着,然后通过这若干个模型的投票,来确定最后的结果,就是bagging的简单介绍;这样将若干个弱分类器通过投票就变成了一个强分类器,准确度更高。另外,通过可放回的抽样,保证了这个套路可以并发进行,从工程的角度来看,可以使计算速度更快;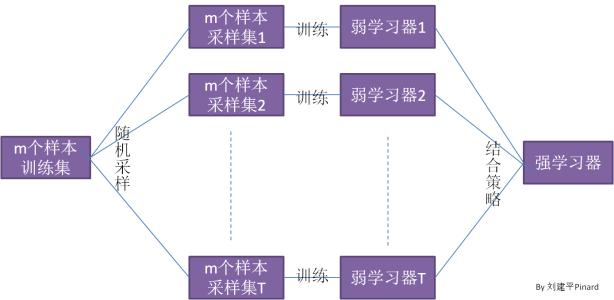
adaboosting是另外一种resample的方法,首先用训练集训练出一个模型,然后用这个模型进行分类,再将分类分错的样本拿出来,训练出第二个模型,第二个模型具有更高的权值,这样反复迭代,可以得到一个强分类器,可以保证全局最优;但是这个策略的问题是,如果有一些异常值,就会导致整个策略的效果不好;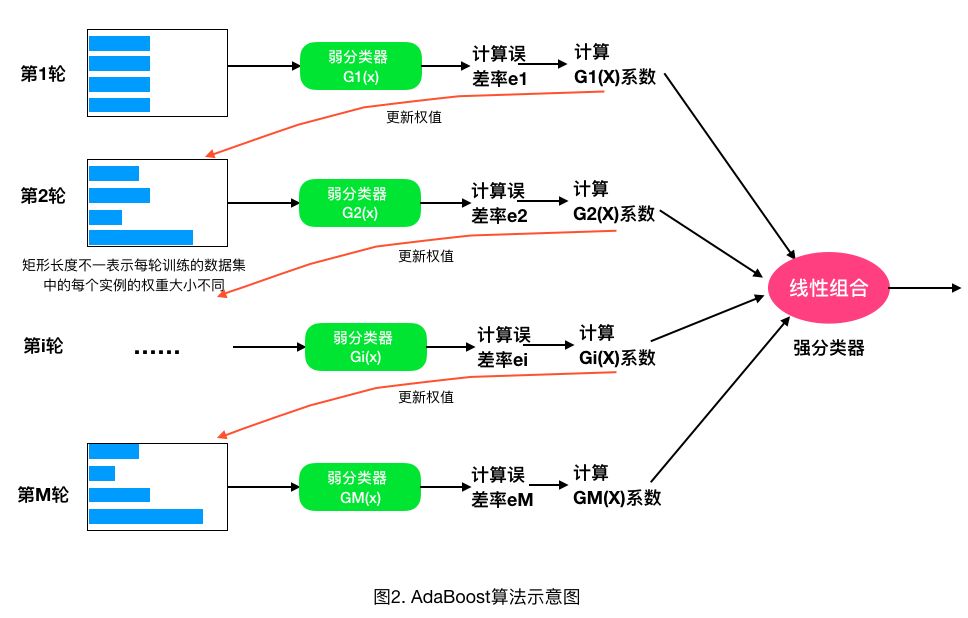
其他还gbdt,xgboost,等之后系统的看一下的时候,再来写吧;
然后记一下最近看到另外一篇文章,通过以下方法可以有效提升机器学习的准确度:
1. 增加更多数据
2. 处理缺失值和异常值
3. 特征工程学,a.归一化,b.把不均匀分布变成正态分布或其他,c.分箱,d.建新特征
4. 特征选择,pca, lca等,可视化,
5. 用多种算法
6. 调整参数
7. 集成学习
8. 交叉验证
这里以备以后复习;