大模型2023
从前年11月份开始,gpt带来的这股浪潮,我相信最终会把整个业界都完全彻底的改变掉,但是国内其实相对来说,还是落后太多,主流的玩家基本没有;
晚了一年,我也想踏上这一路晚风,主要关注于大模型的应用;

从前年11月份开始,gpt带来的这股浪潮,我相信最终会把整个业界都完全彻底的改变掉,但是国内其实相对来说,还是落后太多,主流的玩家基本没有;
晚了一年,我也想踏上这一路晚风,主要关注于大模型的应用;
加入蚂蚁3年,看看上一条blog还是20年11月,现在是23年12月31号,居然是3年一条blog都没有写,真是遗憾,虽然这三年确实不是什么美好的回忆,但是个人真的也是放弃了自己,今天是23年的最后一天,希望明年能够顺顺利利,个人也能成长!
一个成熟的标签系统在公司进行到一定阶段,是一定需要有的,这样可以减少大量的重复劳动,然后同时保证公司可以更有效的利用资源,避免各部门重复造轮子,产生较多的人群包。在我理解中,这个系统应该包含几个功能:
标签管理:主要涉及标签树的建立,底层标签的管理
人群抽取&人群配置:主要涉及根据标签生成对应的配置,
查询引擎:主要涉及根据人反查标签,以及根据标签反查人,
人群分析:主要涉及各人群的聚集分析,行为漏斗,行为轨迹分析等等
标签管理,主要解决两个问题,工程上,解决标签按照标准格式录入,策略上,解决标签体系的建立。
工程上主要是涉及到如何通过标准化导入,将不同类型的数据以标准化的形式接入到系统,中间有个中间层做transfer,通过transfer之后,统一以标准化的方式转入数据引擎,同时在标签体系加上一个标签ID,这个标签ID就是我们日常维护标签体系,也是我们日常维护的基础集合。
策略上,如何从建立用户画像这个问题去思考这个事情,首先分为两类,一类是通用的用户画像,包括年龄地域性别等等,另外一类是定制化的用户画像,可以按分APP或者分组的方式来做这件事情。用户画像,这个也可以完整的分享一下。
人群抽取和人群配置,这个是一个页面配置平台,主要是交互的设计,主要操作时如何通过配置的方式将标签的操作生成一个json出来,这个会涉及几块,一块是人群抽取的交互逻辑,一块是任务管理,人群抽取主要解决根据目前已有的标签系统来生成对应抽取的配置代码(包括标签之前逻辑,抽取的频率,标签功能提供出来的方式),之后任务调度根据这个配置来产出人群结果文件,并提供服务;
查询引擎,主要指当我们产出文件之后,以什么样的形式提供给用户,他可以有以下方式,文件,hive表,服务,广告平台的url,主要由两部分组成,一部分是调度系统,通过人群包的配置,把相关的的人群包生成,这一块主要解决的是性能问题,尤其对一些更新频率较高的人群包,解决性能问题是这个事情的关键,第二部分是提供服务,文件,url,表这一块主要是一些调用接口,只是工作量的问题,另外一块是提供线上查询服务,这一块比较难一点,主要是在线性能的问题。主要解决两类问题:
A) 检查某个device是否在指定人群包里,
B) 检查某个device所在的人群包;
A比较好做,应用面也比较广,比如rta的各种查询等等,b可能会有性能的问题
人群分析是第四部分,这一块主要要解决的问题,是如何通过快速的计算,重新聚拢出相同的逻辑出来,这一块的核心关键是把原来的逻辑能够抽象出来,生成以device id维度的底表,在根据底表做一层一层的聚合,从感觉上来说,更加适合用流式计算来做;
以前我是自己写脚本出来做的,但是目前这个场景感觉更加适合流式计算,其实底表做流式是更加合适一点,当然这个是数据平台做的事情,人群包其实主要还是产出一些统计数据,+漏斗数据,用来分析人群的特点;
我年轻的时候犯过很多问题,其中最大的一个问题是自制力不行,所以在一个重复的坑里跌倒了好多次,差不多10年吧,比较坑,也比较扯淡,浪费了人生很重要的10年,那10年我特别痛苦,因为我知道我在犯错,但是我也不知道怎么爬起来,尝试了很多遍,然后最后终于通过一个特别被动的方式来实现了,这种一定不是我想要的方式,
现在其实是第二个阶段,最近5年,虽然很多事情有了挺大的进步,但是又进入了一个误区了;发现最近5年好像每年都是在原地转圈圈,每年列差不多相似的计划,然后每年也没有怎么执行,一年又一年,时间很快就过了,最近5年看似发生了好大的变化,但是目前来看,还不如之前5年进展快,因为没有多少实质性变化;
你在原地停留的时间越长,你发现自己的进步不是提升了,而是在下降;逆水行舟,不进则退,所以要做新的5年计划;
然后我觉得其中最重要的区别是在于,我没有分阶段来看这些事情,所有的事情都是起个临时计划,然后临时计划做到一半,就不做了,下次又重新开始做新的,所以基本上等于老是在做重复运动,所以还是要按阶段来做事情
参考这个
工单复盘
光阴似箭,距离工单系统上线6,7个月了,扪心自问,我觉得这个设计并不是特别的好,或者说是比较的糟糕;当时主要有三个问题,第一个是设计了一个系统,这个系统过设计了;第二个是在于人被划走之后,还是选择继续操作,所以导致时长特别长;第三个问题在于当人员减少的时候,没有快速的降低标准,把人招进来,不管在任何场景下,人都是第一位的;
所以我以后就只做两件事么,一个是长远来看有意义的事情(加上方法论),每天都要做一点点,一个是人,人主要是招人,一定要把人放在一个比较重要的位置;
所以工单没啥好总结的,不要过设计,要想一个长期的计划,然后看他的每一步都有哪些亮点,然后逐步去实现他;
营销这个其实也没啥好说的,过去说的都是比较简单的营销系统,裂变什么的一定要搞清楚;其实城市模型,这样也没有什么好说的,无非就是自动化一件事情;所有的事情,都要站在以后ai的角度去看,这样得到的结果可能会更好;什么都想想,如果以后这一个用机器来做了,怎么办;搞一些糙的方法论;
我觉得之后最重要的事情,还是今日事今日毕;
process on
好的方法论
1. 每天早上想5件事,然后当天把这5件事做完,今日事今日毕
2. 给一个3个月目标,一个月计划,然后拆成可执行点,给排期,去做;
3. why,how,what
4. pdca,plan,do,check,act
5. 金字塔,scqa,背景,冲突,疑问,回答
6. 用户价值,商业价值,用户价值,可复制
7. 使命,愿景,多个目标(安全,体验,效率,产品),每个目标的核心问题,每个问题的抓手,基石,团队
8. 数立方
9. 营销,新老用户分层,乘推乘,交接瑞幸,vipkid,ofo,摩拜等的操作手法
10. 运营组织架构,
11. 配置化思想
12. Omega.js abtest
13. 常见机器学习方法kmeans,knn
14. 节奏,终局目标,中间目标,节奏
我的用户价值:
1. 不错的技术功底,从0到1和从1到N的系统都能很快的适应;有技术积累,执行力强,可以很快的搭基础系统;搭建稳定性强;
2. 从技术出发,对产品&业务都有较强了解,可以从更高角度看问题,知道如何用技术能够最快的推动业务
我的商业价值:帮助业务推动产生的价值远远高于我的薪水
我的可复制性:营销+行业
这个自从不能写鸡汤之后,这个文章就真是难写,写什么都是很水的感觉,纠结了很久,我决定仿照源哥的操作方式,来写一篇代码文;
17年8月,我写了一篇曲线相似的文章,主要是用来判断两条股票走势,这是基于一条基本理论,历史是相似的,你找到类似的的趋势,将来会有大概率往这个方向去发展,当时讲了若干种方法,本文主要讨论这个操作的实现;
做这个事情主要分为两步,第一步是获取股票历史数据,第二步是算出相似度
获取历史数据主要是以下操作,我大部分获取数据的方式是通过python来获取
1. 首先安装python环境,我一般装python2.7,python里面2.*和3.*是完全不一样的,这个baidu一下就可以了;
2. 然后装python的pip或者easy_install,python大部分的库都是可以通过这两个来很方便的装上的,类似于yum的操作;
3. 装主要的机器学习库,如matplotlib,numpy,sklearn,scipy, tensorflow,caffe2,python是目前来说机器学习的主流语言,常用的机器学习库都有,这些库里不仅有csv的常用操作,如类似于read_csv这些,也有各种画图操作,还有基本上你书上学到所有算法,都能在python库里找到,如简单的knn,kmeans,复杂一点的集成学习等,包括算auc,roc都能,基本都可以;这个稍微麻烦一点就是依赖库的安装,国外的源比较慢,国内的用douban,阿里,清华的源都可以;然后还有一种其他的方式,装Anaconda,对所有的语言来说,最复杂的是装环境,anaconda就是解决这个问题,他把主流的操作都封到一个python版本里,虽然文件大一点,但是只要装好了,就全部装好了;
4. 获取股票数据,我一般用tushare,tushare可以理解是一个抓取库,他把网上一些股票来源,如新浪,网易财经等,获取后做完数据清洗,作为公共的数据来源;需要先安装pandas,然后easy_install tushare就可以了,如下图,get_k_data,filename是股票id,然后给出起始时间就可以了;网站是http://tushare.org/![]()
如下图所示,就是一个股票的数据,包括open,close等参数;
然后我们进入第二个阶段,就是实现阶段,那篇文章主要是实现两条曲线相似性 http://hlhome.xiaojukeji.com/forum.php?mod=viewthread&tid=153;
这里就快速过一下,因为之前讲过,或者可以百度:
1. 欧式距离
2. 皮尔森
3. 加速度算面积
4. 狗绳距离,具体见下图
我们随便拿出两段数据,画个图显示一下:
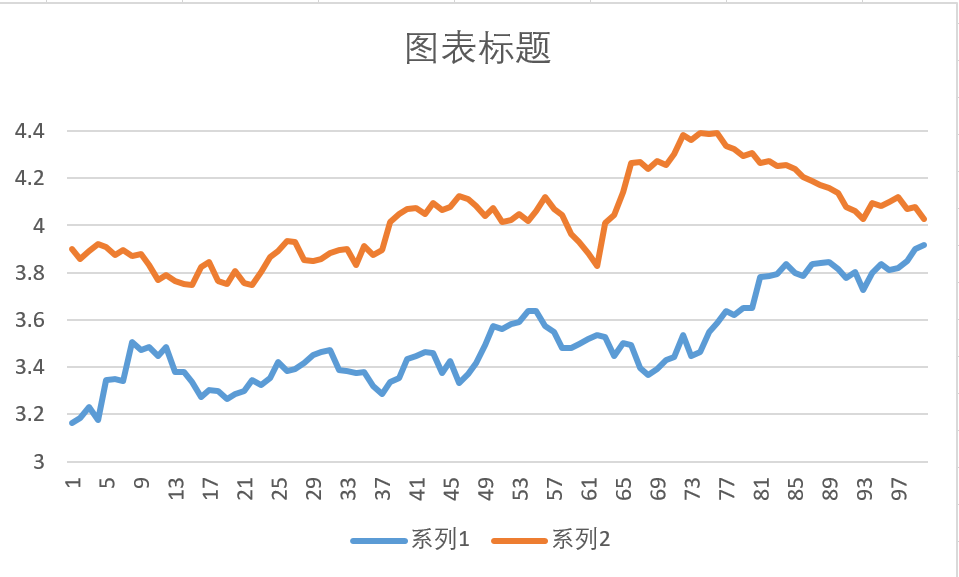
我们那159915的数据,然后根据过去3年的数据,每100天作为一个图像输入,第一个作为基准输入,然后从节点200开始,每20天作为一个时间切片的起始点,来算两段图像的相似度,把距离最短的保存起来,然后用于展示,最后的图像如下图所示;
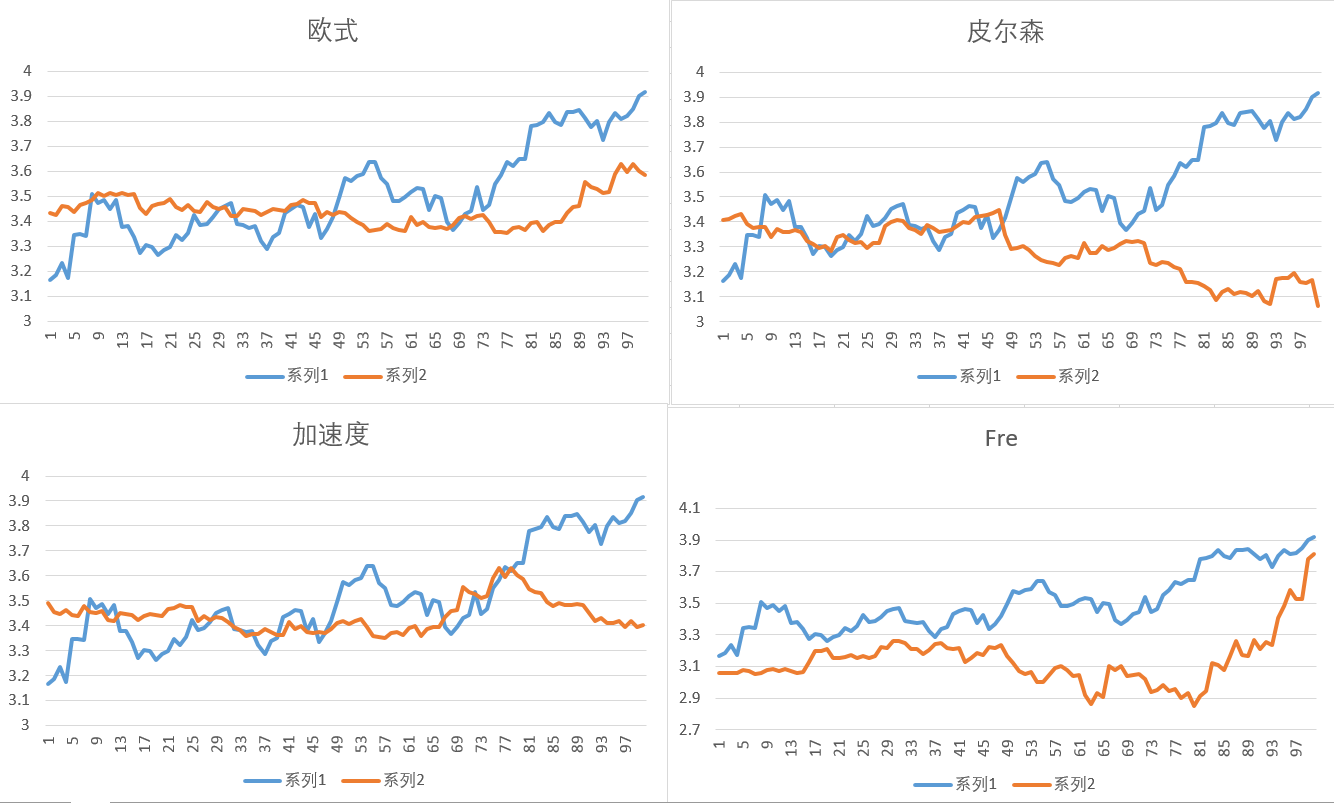
目前来看,狗绳算法效果稍微好一点;
接下来,我说另一个数据处理一定会做的事,就是归一化,常用的归一化方式可以百度
我这里用的Min-Max Normalization,也就是x∗=(x−min)/(max−min),这样就把x归到0-1之间去了,这个算法不好的地方,就是一旦有一个极值,数据就不好看了,因为分母特别大;
其他算归一化的方式,还有zscore(x∗=(x−μ)/σ),这是认为数据符合正态分布的;这些实现numpy里面都有,然后得到了下图;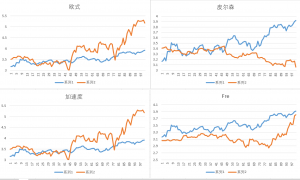
还是有点不像,所以说曲线相似也不好搞,而且股票还有一些问题,因为你不能用全部的股票集来算训练,因为很容易过拟合(想想为啥容易过拟合),我一般做到这里,然后用相似函数作为核函数用kmeans来聚类,或者直接选取几种图形来算相似度,也是解法,
发现字数够了,然后后面的事,我抽空继续写写