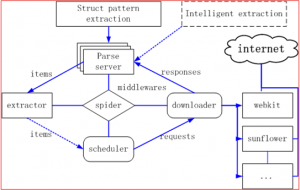
数据可视化
从2012年底开始我其实就在做数据可视化相关的工作了,只是可能当时候可能没有意识到,那一年基本上都是开始从最基础的开始摸索,也是多亏了大公司,给了这么多机会可以探索;
其实第一个问题就是,为啥要做数据可视化了?
在我的理解中,数据是一切决策的起点,也是一切决策的终点,我经常自己来pdca来做事情,在plan的阶段和在check的阶段,都是需要精确的数据来做支持的;但是我们日常看到的数据,指标很多,有些是重要的,有些是不重要的,他们都是平躺在二维世界的平面里,你看不出也不知道哪些是重要的,在这个过程中,一个好的数据分析师需要化繁从简,获取最重要的数据,将他们展示出来,提供决策和评估,这就是数据可视化的作用和意义;
可能分为这么阶段:
1. 最开始,什么数据都没有,大家都是闷着头进行分析,做什么都是靠拍脑袋
2. 获取最基本的数据,通过文件报表形式或者是邮件进行转发,数据很多且比较繁
3. 将数据从文件中立体出来,变成图表形式;
因为人们都是很懒的,而且图表能够更加直观的表现出趋势,所以人们更加愿意先通过图形来看结果;
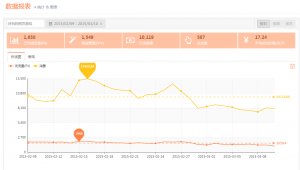
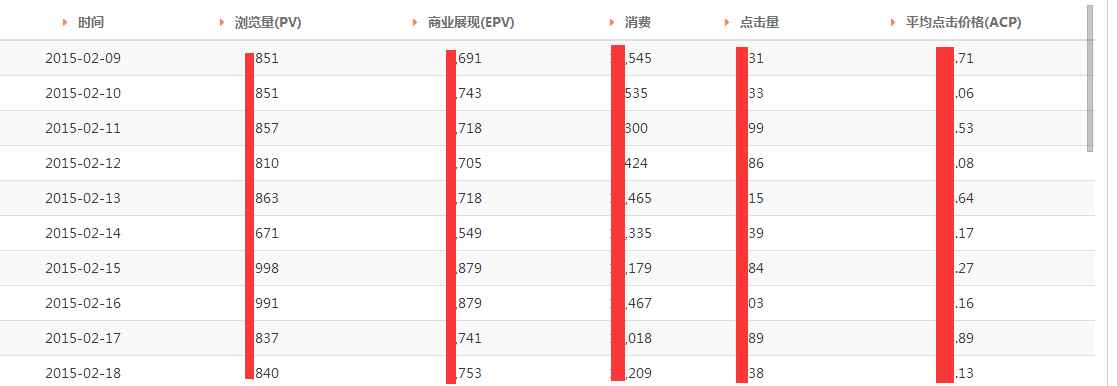
图形能够更快的将结果显示出来,也能更好的说明问题;
然后是how:
1. 最重要的是选数据进行展示,最核心的业务数据进行展示,抓取对方想要的,这就是关键;
2. 数据展示,最开始用的是自己写的,bootstrap加几个开源的charts库,现在看来echarts挺好的,当初如果视野稍微广一点,也就可以把echarts这个东东整理做做了;
这两点都是非常重要的,对我个人来说,核心数据的选取是最重要的,因为只有对方想要的数据才是有用的数据,自己想出来的数据不是说不重要,但是像乔帮主这种能创造需求的人毕竟是很少数的,更多的还是自己去挖掘需求,去把需求收集起来,然后整理,合并提取,这是大多数需求的来源;这两年倒是经常想转pm去尝试尝试;先高屋建瓴的去看看这个坑应该往哪个方向去挖,然后再不停的从用户的角度去使用产品,应该产品就差不到哪里去;
1. 找对的大方向
2. 用替代思维去使用产品,让流程变得顺畅
3. 抓取核心指标,提升时效性,准确性;
4. 整理需求而不是发明需求,做大家都常见的点
5. 多组装产品,少发明产品;
6. 先实现基础需求,当基础需求做到极致了,再做高级需求;