这个自从不能写鸡汤之后,这个文章就真是难写,写什么都是很水的感觉,纠结了很久,我决定仿照源哥的操作方式,来写一篇代码文;
17年8月,我写了一篇曲线相似的文章,主要是用来判断两条股票走势,这是基于一条基本理论,历史是相似的,你找到类似的的趋势,将来会有大概率往这个方向去发展,当时讲了若干种方法,本文主要讨论这个操作的实现;
做这个事情主要分为两步,第一步是获取股票历史数据,第二步是算出相似度
获取历史数据主要是以下操作,我大部分获取数据的方式是通过python来获取
1. 首先安装python环境,我一般装python2.7,python里面2.*和3.*是完全不一样的,这个baidu一下就可以了;
2. 然后装python的pip或者easy_install,python大部分的库都是可以通过这两个来很方便的装上的,类似于yum的操作;
3. 装主要的机器学习库,如matplotlib,numpy,sklearn,scipy, tensorflow,caffe2,python是目前来说机器学习的主流语言,常用的机器学习库都有,这些库里不仅有csv的常用操作,如类似于read_csv这些,也有各种画图操作,还有基本上你书上学到所有算法,都能在python库里找到,如简单的knn,kmeans,复杂一点的集成学习等,包括算auc,roc都能,基本都可以;这个稍微麻烦一点就是依赖库的安装,国外的源比较慢,国内的用douban,阿里,清华的源都可以;然后还有一种其他的方式,装Anaconda,对所有的语言来说,最复杂的是装环境,anaconda就是解决这个问题,他把主流的操作都封到一个python版本里,虽然文件大一点,但是只要装好了,就全部装好了;
4. 获取股票数据,我一般用tushare,tushare可以理解是一个抓取库,他把网上一些股票来源,如新浪,网易财经等,获取后做完数据清洗,作为公共的数据来源;需要先安装pandas,然后easy_install tushare就可以了,如下图,get_k_data,filename是股票id,然后给出起始时间就可以了;网站是http://tushare.org/![]()
如下图所示,就是一个股票的数据,包括open,close等参数;
然后我们进入第二个阶段,就是实现阶段,那篇文章主要是实现两条曲线相似性 http://hlhome.xiaojukeji.com/forum.php?mod=viewthread&tid=153;
这里就快速过一下,因为之前讲过,或者可以百度:
1. 欧式距离
2. 皮尔森
3. 加速度算面积
4. 狗绳距离,具体见下图
我们随便拿出两段数据,画个图显示一下:
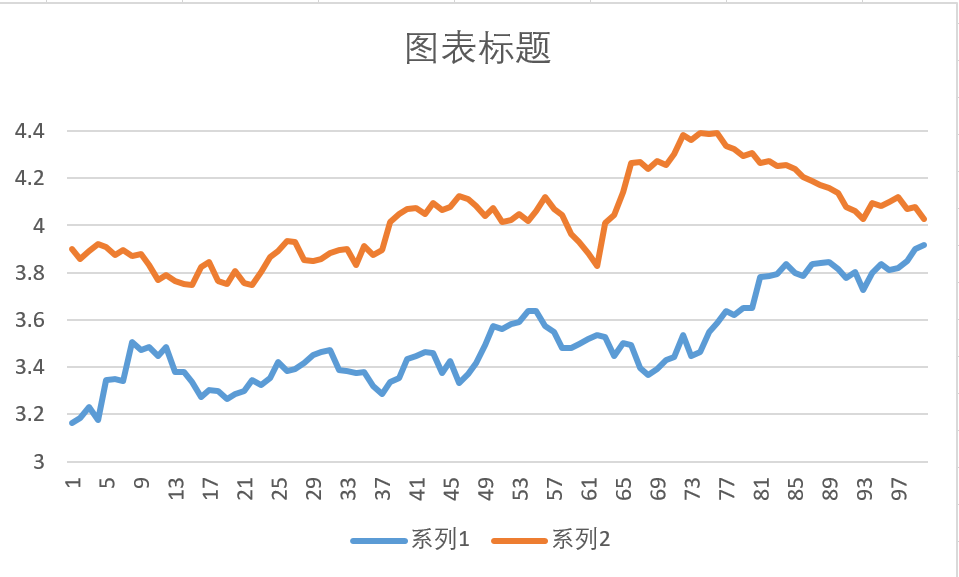
我们那159915的数据,然后根据过去3年的数据,每100天作为一个图像输入,第一个作为基准输入,然后从节点200开始,每20天作为一个时间切片的起始点,来算两段图像的相似度,把距离最短的保存起来,然后用于展示,最后的图像如下图所示;
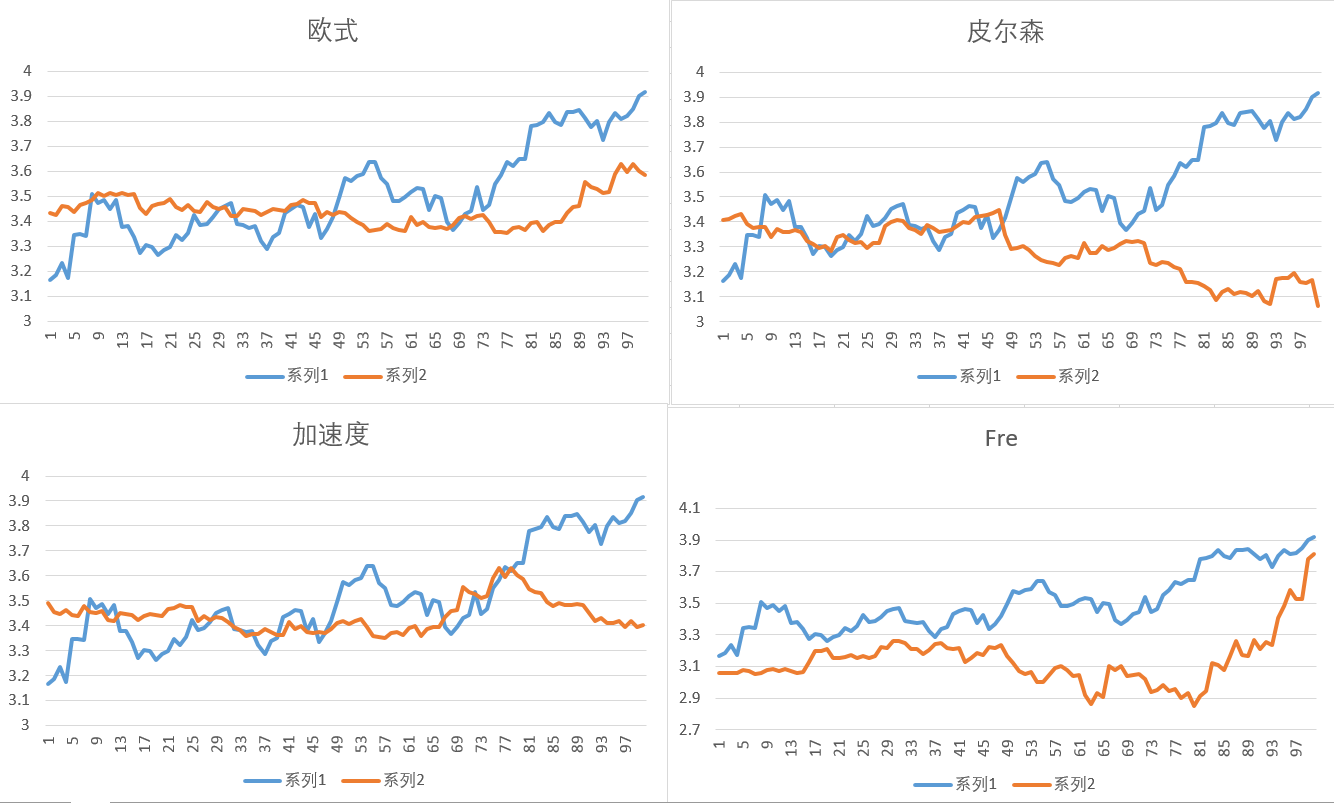
目前来看,狗绳算法效果稍微好一点;
接下来,我说另一个数据处理一定会做的事,就是归一化,常用的归一化方式可以百度
我这里用的Min-Max Normalization,也就是x∗=(x−min)/(max−min),这样就把x归到0-1之间去了,这个算法不好的地方,就是一旦有一个极值,数据就不好看了,因为分母特别大;
其他算归一化的方式,还有zscore(x∗=(x−μ)/σ),这是认为数据符合正态分布的;这些实现numpy里面都有,然后得到了下图;
还是有点不像,所以说曲线相似也不好搞,而且股票还有一些问题,因为你不能用全部的股票集来算训练,因为很容易过拟合(想想为啥容易过拟合),我一般做到这里,然后用相似函数作为核函数用kmeans来聚类,或者直接选取几种图形来算相似度,也是解法,
发现字数够了,然后后面的事,我抽空继续写写